WEEK 1
13 - 19 JUN
We have a bunch of Codex Mendoza files from our previous GSoC project (more files are going to be added soon):
- Simplex (209): glyph is a whole unity
- Compound (364): glyph is a block of minor unities
- Atomic (714): minor unities isolated
- Iconography (12): another elements depicted, not logographyc glyphs but related
- Everything (1295): all previous files in same folder
- Augmented (6431): all glyphs of previous folder were shifted/rotate and generate an artificial expanded dataset made by Tarun.

This is an example of augmented compound glyph ‘Acatepec’
A successful match for the algorithm is determined by figure colours and its shape/position. We consider framing (250x250 or 500x500) a couple of testing images, with a small margin and transparent background or emulating light-brown paper (stored as PNG instead JPG/JPEG files to maintain transparency):

Ahuatepec original glyph in JPG, and transparent and paper-color glyphs 500x500 stored as PNG extension
Another problem we are dealing with is the optimal way to name files. Theoretically, the name of the file is irrelevant when the image is processed, but we want to link it to its glyphic value and with potential entries in Visual Lexicon.
There are two options for this task:
- Implement a way to obtain the info from the Drupal DB, with the cost of time and complexity that may arise.
- Extract from filenames so Python code can process it as a kind of metadata, print it on screen and build the web link for entries in the dictionary.
The second option could be something like this: name-type-pagination-source-extrainfo.png
I.E. :
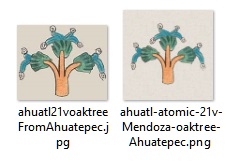
ahuatl-atomic-21v-Mendoza-oaktree-Ahuatepec.png
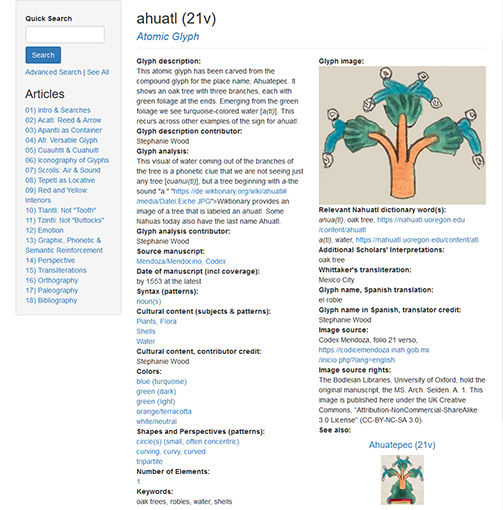
But we have the Visual Lexicon entries under this form:
https://aztecglyphs.uoregon.edu/content/ahuatl-21v
or from other codices (AGN, Tierras, vol. 1871, exp. 1 = t18711):
https://aztecglyphs.uoregon.edu/content/20-matl-t18711
So in our example, the ‘real’ image-related expected link is:
https://aztecglyphs.uoregon.edu/content/ahuatl-21v
From there, there is an internal link to Online Nahuatl Dictionary:

https://nahuatl.uoregon.edu/content/ahuatl
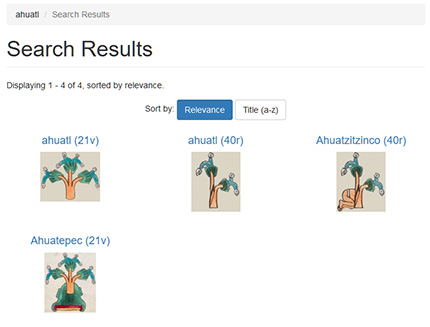
Another temporal solution should be just get the glyph name in the first filename position an establish a search-link, so user can check all available entries in Visual Lexicon:
https://aztecglyphs.uoregon.edu/fulltext-quick-search?search_api_views_fulltext=ahuatl
WEEK 2
20 - 26 JUN
‘Matrícula de Tributos’ (ca. 1520-30) is a best candidate for expand the dataset (as we have so few examples of each glyph) but the algorythm showed a not so bad accuracity but failed when the same glyph was light or very dark colored. This is the main problem to deal with Matrícula de Tributos. It has 31 painted sheets of indigenous paper, amate (while Codex Mendoza, ca. 1540 was made of European paper). Some sheets of Matrícula de Tributos have lost some parts of the fibers and having a light-brown color due its antiquity and conservation. Although, some painted figures are partial lost or color-vanished, so we decided to edit them with software and get the most possible approach to its ‘original’ painting brightness.
These are some of our results using the free images available at World Digital Library:

Matrícula de Tributos, sheet 1, very damaged

Matrícula de Tributos, sheet 29. Black, green, blue and red are the most vanished
Here, a quick example of a glyph cropped and compared with our previous dataset:

Comparison between codices and digital treatments: A. Non-retouched glyph ‘Tecualoyan’ in Codex Mendoza; B. ‘Tecualoyan’ in 500x500 paper-color background; C. Non-retouched glyph ‘Tecualoyan’ in Matrícula de Tributos; D. Same glyph color-contrasted; E. Previous example cropped with a 500x500 paper-color background. F. Previous example mirrored.
WEEK 3
27 JUN - 3 JUL
Now, I am going to crop each figure from each Matrícula de Tributos’ sheet, starting from left-up corner, going down and so on until the right-down corner. I crop all elements depicted (iconographic, glyphic or numerals). But, each ‘compound’ or glyphic-block is cropped as a whole. Numerals presents in glyphs or iconography (as a graphic part) are cropped together with the main figure if they are visual integrated, as these examples:
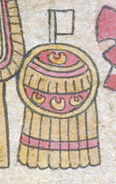
20 number (pantli, as a white flag) in the top of a chimalli-shield

400 (20x20) number (centzontli, as a kind of black hair comb) in the top of a white blanquet
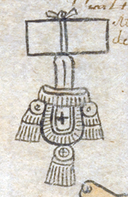
8000 (20x400) number (xiquipilli, as a white bag) under a paper bundle
I will crop them in atomic glyphs later, but now total result is 849 main elements.
I am going to make a test before start removing peripheral details and determining which is the best type of background for a high match with the original dataset:
I choose two particular glyphs due to their similar shape between codices but one is color-vanished and another one is damaged. One is Ahuatepec glyph (Matrícula de Tributos, sheet 4) which is present in Codex Mendoza, 21v.

Left: Ahuatepec in Matrícula de Tributos, sh.4. Right: Glyphs from Mendoza match-expected
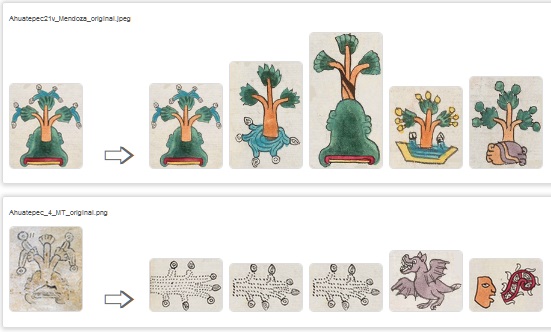
These are the matching results with old datapump. As we can observe, Mendoza glyph matchs with itself. But Matrícula de Tributos example is light-colored and vanished and matches with a non-color, light-brown full background glyph
Now, let’s modify Ahuatepec glyph from Matrícula de Tributos.

Some diferent backgrounds and artificial glyph colored (last one example is the most resembled to Mendoza’s example)
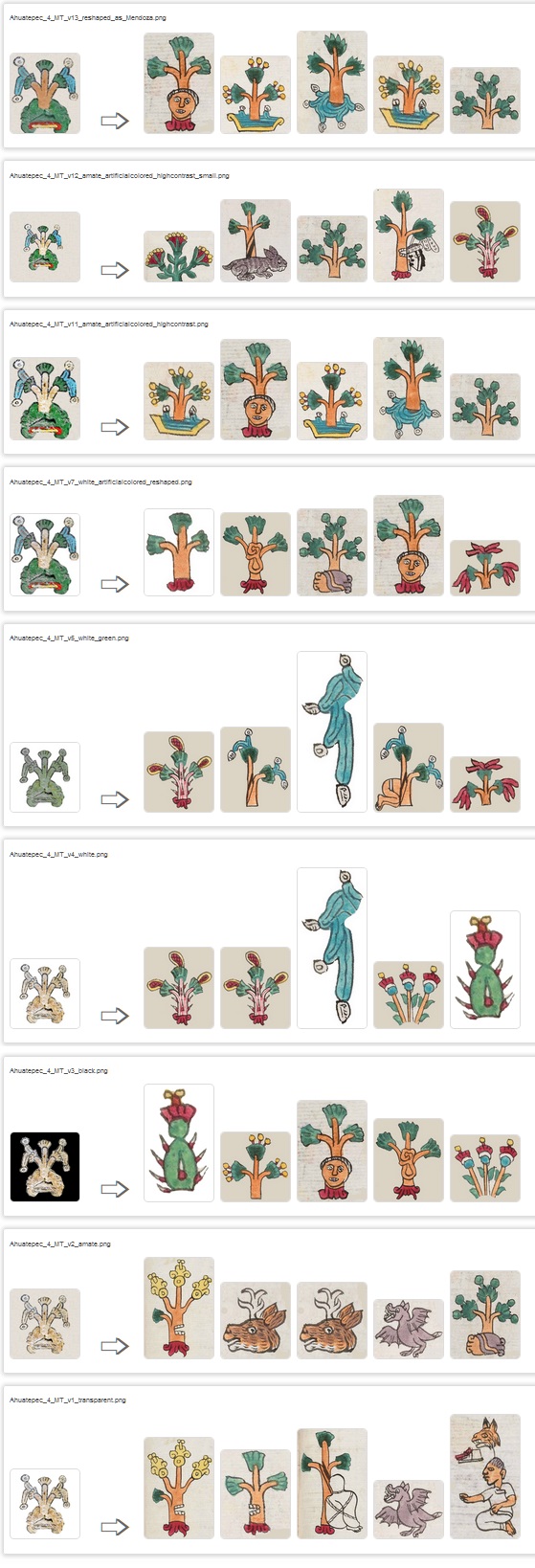
As we can see, none of them match Ahuatepec or Ahuatl as in Mendoza (except the full-green glyph and white background in the 2nd -Ahuatl- and 4th position -Ahuatzitzinco- where they surprisingly coincide). Transparent or paper-colored backgrounds are the most accurated when the glyph has no artificial color. When artificially colored, the glyph matches other trees and plants in a ‘cross’ shape. Some water elements are present. Trees and tree-like plants are very difficult to distinguish, even for human eye due to the high complexity of peripheral elements, resulting in different names of trees or species.
The other one is Oztoma (Matrícula de Tributos, sheet 1: partially damaged) but related with Oztotl in Codex Mendoza, 24v. And these are the glyphs match-expected:

So, I modify damaged glyph Oztoma as previous Ahuatepec examples.

Some modified Otzoma glyphs. Last one is artificial colored as expected
And these are the results:
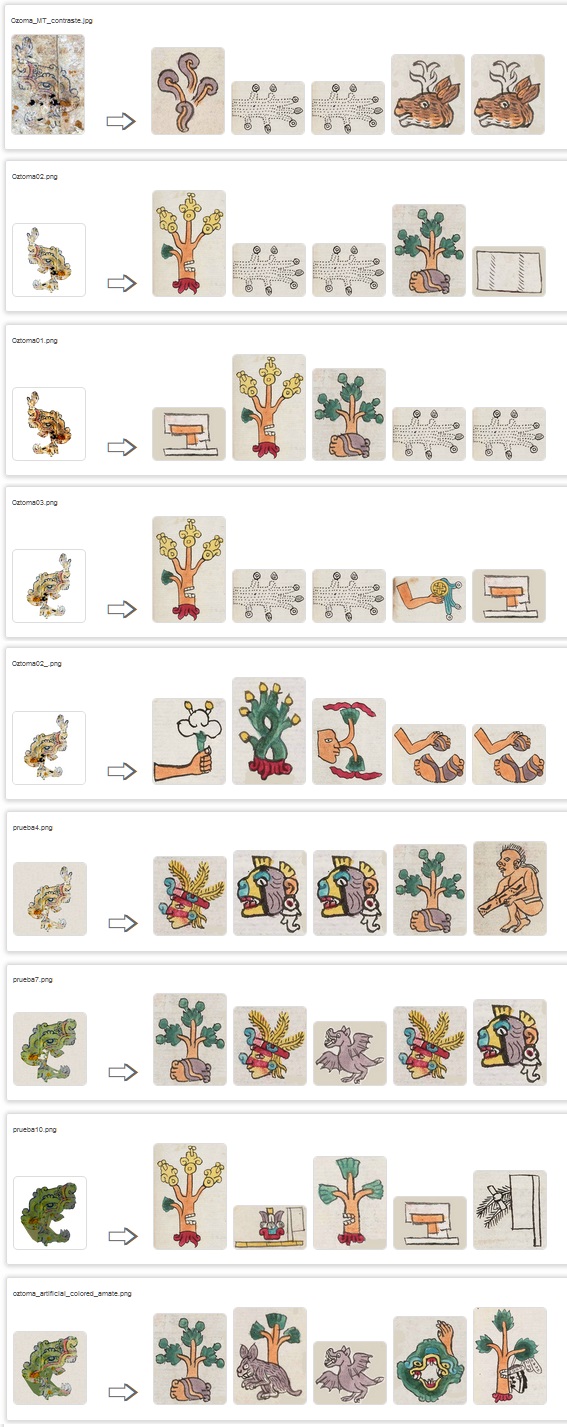
As we can observe, none of them matched. Only last example, artificial colored, matches in 4th position with a frontal-face Otzotl with a hand in the right-top corner, but hand was erased from this test-example.
WEEK 4
4 - 10 JUN
These weeks, I am going to create glyph-files until Mid. Evaluation. I will try to do as much as I can, but trying at least to focus in toponymic glyphs.

This is just an example after contrast, crop and paste in a 500x500 paper-like background (Matrícula de Tributos, sheet 4)
WEEK 5
11 - 17 JUL
Stephanie Wood send me a new datapump this week, stored by iconography, simplex, compound and atomic glyphs. Ignoring those repeated, there are 2012 image files, plus 62 digital painted glyphs.

Digital glyph Oztotol from new datapump

Oztotol matches in previous datapump
I am still cropping minor unit-glyphs, as it is a bit challenging crop vanished outlines.
WEEK 6
18 - 24 JUL
I am finishing cropping Matrícula de Tributos and try to label each glyph with its proper name-value. Meanwhile, I am finding glyphs from Osuna Codex (ignoring iconography by now).
I got 81 sheets from Biblioteca Nacional de España. This is an example of a sheet and its light-color provided by one of BNE versions:

Osuna Codex, 35r

Osuna Codex, 35r, detail
And this is the result after cropping and apply a 500x500 paper-colored background

Left: Non-edit glyph Ocotepec, Osuna Codex 35r. Right: after edition
When Ocelote head from Osuna Codex is tested with diferent backgrounds and enlargements, best match is centered with generous margings and white/transparent background.
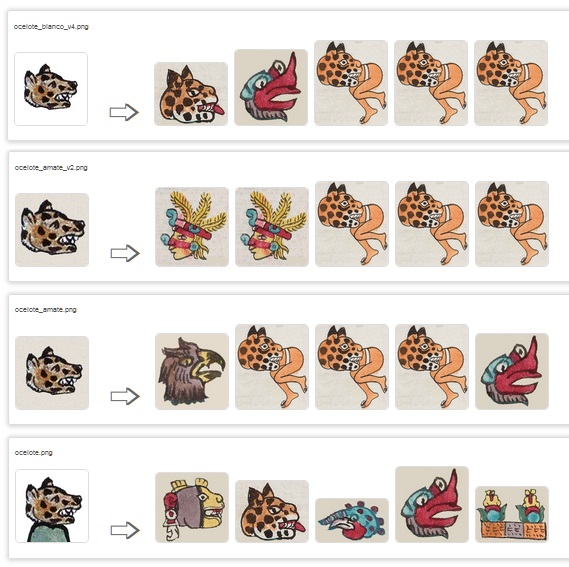
First ocelote head with a white background seems to be the most accurated. All its results are related with ocelote, but 2nd one is Ehecatl’s face.
Meanwhile, I prepare the new datapump from Mendoza Codex to upload. As soon as I finish Matricula de Tributos, all the files will be uploaded too.
WEEK 7 Mentors and contributors can begin submitting Phase 1 evaluations
25 - 31 JUN
This week I am going to upload a new datapump from Matricula de Tributos, available here.
And mix it with previous GSoC2021 dataset from Mendoza and new additions provided by my mentor Stephanie Wood.
WEEK 8
1 - 7 AGO
This 2 weeks I am going to change previous code version, add new code for link images with Visual Lexicon entries (search results), get glyph name from filename, and convert Cosine distance into similarity percentage. All the code will be uploaded to Red Hen Lab server and here at my 2022 Github Repo
WEEK 9
8 - 14 AGO
This is the result after modify “app.py” and “app.html” files:
app.py
import os, re, shutil
import urllib.request
from flask import Flask, flash, request, redirect, url_for, render_template, session, json, jsonify
from werkzeug.utils import secure_filename
from flask_executor import Executor
from flask_socketio import SocketIO, emit
import tensorflow.keras
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.imagenet_utils import decode_predictions, preprocess_input
from tensorflow.keras.models import Model
import numpy as np
import tensorflow as tf
from scipy.spatial import distance
import time
# image file extensions allowed
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif', 'webp'])
#UPLOAD_FOLDER = 'static/uploads/'
UPLOAD_FOLDER = '/tmp/aztecglyphrecognitiontempuploads/'
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
app = Flask(__name__)
app.secret_key = "secret key"
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
app.config['MAX_CONTENT_LENGTH'] = 16 * 1024 * 1024
app.config['SECRET_KEY'] = 'mySecretKey'
executor = Executor(app)
socketio = SocketIO(app)
base_models = tf.keras.applications.MobileNet()
features = []
images_website = []
feat_extractor = Model(inputs=base_models.input, outputs=base_models.get_layer("reshape_2").output)
@app.route('/')
def index():
return home()
#check if upload folder exists and upload images
@app.route('/', methods=['POST'])
def upload_image():
if os.path.exists(UPLOAD_FOLDER):
if len(os.listdir(UPLOAD_FOLDER)) > 0:
shutil.rmtree(UPLOAD_FOLDER)
os.makedirs(UPLOAD_FOLDER)
else:
os.makedirs(UPLOAD_FOLDER)
clientId = request.form.get('client_id')
files = request.files.getlist("file")
meta = json.loads(request.form.get('meta'))
for file in files:
imageId = meta[file.filename]
filename = secure_filename(file.filename)
imagePath = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(imagePath)
executor.submit(analyze_image, imagePath, file.filename, clientId, imageId)
return render_template('blank.html')
#show default html
def home():
return render_template('app.html')
#analyze image dataset before starts
def extract_features():
images_path = 'static/samples/'
image_extensions = ['.jpg', '.png', '.jpeg', '.gif', '.webp']
max_num_images = 1000000
images = [os.path.join(dp, f) for dp, dn, filenames in os.walk(images_path) for f in filenames if os.path.splitext(f)[1].lower() in image_extensions]
images_website.clear()
images_website.extend([os.path.join(images_path, f) for dp, dn, filenames in os.walk(images_path) for f in filenames if os.path.splitext(f)[1].lower() in image_extensions])
if max_num_images < len(images):
images = [images[i] for i in sorted(random.sample(xrange(len(images)), max_num_images))]
print("keeping %d images to analyze" % len(images))
tic = time.time()
features.clear()
for i, image_path in enumerate(images):
if i % 100 == 0:
toc = time.time()
elap = toc-tic;
print("analyzing image %d / %d. Time: %4.4f seconds." % (i, len(images),elap))
tic = time.time()
img, x = load_image(image_path);
feat = feat_extractor.predict(x)[0]
features.append(feat)
print('finished extracting features for %d images' % len(images))
#get similarity results of closed images and split filenames for link them to Visual Lexicon website
def analyze_image(imagePath, originalFileName, clientId, imageId):
print("analyzing image: %s" % (imagePath))
img, x = load_image(imagePath)
imga = feat_extractor.predict(x)[0]
results, similarity = get_closest_images(imga, 6)
n_similarity =0
payload = dict()
payload['results'] = []
payload['similarity'] = []
payload['image_id'] = imageId
payload['glyphname'] = []
for idx in results:
head, tail = os.path.split(images_website[idx])
file_glyphname = re.split('[0-9]|[_]|[-]|[(]|[,]|[.]', tail, maxsplit=1)
payload['results'].append(images_website[idx])
payload['similarity'].append(similarity[n_similarity])
n_similarity = n_similarity+1
payload['glyphname'].append(file_glyphname[0])
socketio.emit(clientId, json.dumps(payload))
def load_image(path):
img = image.load_img(path, target_size=base_models.input_shape[1:3])
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return img, x
def get_closest_images(imga, num_results=6):
distances = [ distance.cosine(imga, feat) for feat in features ]
idx_closest = sorted(range(len(distances)), key=lambda k: distances[k])[0:num_results]
similarity = sorted((int(round((1-(distance.cosine(imga, feat)))*100, 0)) for feat in features), key=int, reverse=True)[0:num_results]
return idx_closest, similarity
extract_features()
if __name__ == "__main__":
app.run(host='0.0.0.0', port=os.environ.get('PORT', '5000'))
app.html
<!DOCTYPE html>
<html>
<head>
<title>Visual Recognition of Aztec Hieroglyphs</title>
<!--<link ="stylesheet" href="style.css" reltype="text/css"> -->
<style type="text/css">
body {
background-color: #fefefe;
font-family: Arial, Helvetica, sans-serif;
padding: 20px;
font-size: 14px;
}
// HTML cosmetics
label {
display: inline-block;
background-color: royalblue;
color: white;
padding: 0.5rem;
font-family: sans-serif;
border-radius: 0.3rem;
cursor: pointer;
margin-top: 1rem;
-webkit-touch-callout: none;
-webkit-user-select: none;
-khtml-user-select: none;
-moz-user-select: none;
-ms-user-select: none;
user-select: none;
}
.clearButton {
background-color: royalblue;
border: none;
color: white;
padding: 8px;
text-align: center;
text-decoration: none;
float: right;
clear: both;
font-size: 14px;
border-radius: 0.3rem;
margin-top: -40px;
}
.collectionContainer {
background-color: white;
margin-bottom: 20px;
border: 1px solid #ddd;
border-radius: 5px;
padding: 10px;
-webkit-box-shadow: 1px 1px 5px 2px rgba(0, 0, 0, 0.15);
box-shadow: 1px 1px 5px 2px rgba(0, 0, 0, 0.15);
}
.collectionContainer img {
border-radius: 8px;
object-fit: cover;
margin-right: 10px;
margin-bottom: 10px
}
.fileName {
font-size: 11px;
color: #555;
padding-top: 8px;
padding-bottom: 16px;
}
.arrow {
font-size: 60px;
vertical-align: bottom;
margin-top: 28px;
padding-left: 20px;
padding-right: 20px;
display: inline-block;
color: #666;
}
.gears {
vertical-align: bottom;
margin-top: 42px;
padding-left: 20px;
}
.noSelect {
-webkit-touch-callout: none;
-webkit-user-select: none;
-khtml-user-select: none;
-moz-user-select: none;
-ms-user-select: none;
user-select: none;
}
.topnav {
overflow: hidden;
background-color: royalblue;
}
.topnav a {
float: left;
color: #f2f2f2;
text-align: center;
padding: 14px 16px;
text-decoration: none;
font-size: 26px;
}
.topnav a:hover {
background-color: royalblue;
color: black;
}
.topnav a.active {
background-color: royalblue;
color: white;
}
</style>
</head>
<body>
<div class="topnav">
<a><img src="https://aztecglyphs.uoregon.edu/sites/default/files/ilhuitlcrop.png" alt="Home" width="80%" height="80%"></a>
<a href="https://aztecglyphs.uoregon.edu/"><b>Visual Lexicon</b></a>
</div>
<br>
<h1><i>Visual Recognition of Aztec Hieroglyphs</i></h1>
<form method="post" action="/" id="form" enctype="multipart/form-data">
<input type="file" name="file" id="file" onchange="submitForm(this)" autocomplete="off" accept="image/gif, image/jpeg, image/png, image/webp" required hidden multiple>
<input type="hidden" name="client_id" id="client_id">
<input type="hidden" name="meta" id="meta">
<label for="file" class="noSelect">Select images to analyze</label><i> (JPG, JPEG, PNG, GIF or WEBP only)</i>
</form>
<br><br>
<button class="clearButton noSelect" id="clearButton" style="cursor:pointer">Clear results</button>
<div id="results"></div>
<div id="noResults">Click the button above to analyze the 6 most accurate glyphs per image</div>
<script src="https://code.jquery.com/jquery-3.5.1.min.js" integrity="sha256-9/aliU8dGd2tb6OSsuzixeV4y/faTqgFtohetphbbj0=" crossorigin="anonymous"></script>
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/socket.io/4.1.3/socket.io.js"></script>
<script type="text/javascript" charset="utf-8">
function uuid() {
return 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function (c) {
var r = Math.random() * 16 | 0, v = c == 'x' ? r : (r & 0x3 | 0x8);
return v.toString(16);
})
}
if (localStorage.getItem('client_id') === null) {
localStorage.setItem('client_id', uuid())
}
clientId = localStorage.getItem('client_id')
// Get results with shocketio via payload.
// PLEASE: change 0.0.0.0:5000 with your public IP or URL website for a production environment
var socket = io.connect('0.0.0.0:5000');
socket.on(clientId, function (data) {
var payload = JSON.parse(data)
$('#' + payload['image_id']).html('')
for (var i = 0; i < payload['results'].length; i++) {
// if we get no info after split filename, tell user. Else, go on...
if (payload['glyphname'][i] == "") {
var img = $(document.createElement('img'))
img.attr('src', payload['results'][i])
img.attr('width', '100')
img.attr('height', 'auto')
img.attr('style', 'border: 1px solid #ddd')
img.attr('title','Sorry, no proper info recovered for this image: ('+Math.abs(payload['similarity'][i])+'% of similarity)')
$('#' + payload['image_id']).append(img)
} else {
var img = $(document.createElement('a'))
img.attr('href', 'https://aztecglyphs.uoregon.edu/fulltext-quick-search?search_api_views_fulltext='+payload['glyphname'][i])
img.attr('target', '_blank')
img.append(
$('<img>')
.attr('src', payload['results'][i])
.attr('width', '100')
.attr('height', 'auto')
.attr('style', 'border: 1px solid #ddd')
.attr('title', payload['glyphname'][i]+' ('+ Math.abs(payload['similarity'][i])+'% of similarity)'))
$('#' + payload['image_id']).append(img)
}
}
})
function clear() {
$('#clearButton').hide()
$('#results').html(' ')
$('#noResults').show()
}
function submitForm(form) {
$('#noResults').hide()
$('#clearButton').show()
var meta = {}
var files = document.getElementById('file').files
for (var i = 0; i < files.length; i++) {
console.log('file name => ' + files[i].name);
var imageId = uuid()
meta[files[i].name] = imageId
var container = $(document.createElement('div'))
container.attr('class', 'collectionContainer')
var fileName = $(document.createElement('div')).html(files[i].name)
fileName.attr('class', 'fileName')
container.append(fileName)
var sourceImage = $(document.createElement('img'))
sourceImage.attr('src', URL.createObjectURL(files[i]))
sourceImage.attr('width', '120')
sourceImage.attr('height', 'auto')
sourceImage.attr('style', 'border: 1px solid #ddd')
container.append(sourceImage)
var arrow = $(document.createElement('span')).html("➩")
arrow.attr('class', 'arrow')
container.append(arrow)
var resultsContainer = $(document.createElement('span'))
resultsContainer.attr('id', imageId)
container.append(resultsContainer)
var loading = $(document.createElement('img'))
loading.attr('src', 'static/gear.gif')
loading.attr('class', 'gears')
loading.attr('width', '60')
loading.attr('height', 'auto')
resultsContainer.append(loading)
$('#results').prepend(container)
}
document.getElementById('meta').value = JSON.stringify(meta)
document.getElementById('client_id').value = localStorage.getItem('client_id')
var form = $('#form')[0]
var data = new FormData(form)
form.reset()
$.ajax({
type: "POST",
enctype: 'multipart/form-data',
url: "/",
data: data,
processData: false,
contentType: false,
cache: false,
timeout: 600000,
success: function (data) {
console.log("SUCCESS : ")
},
error: function (e) {
console.log("ERROR : ", e)
}
});
return true
}
$(document).ready(function () {
$('#clearButton').hide()
$('#clearButton').on("click", function (e) {
e.preventDefault();
e.stopPropagation();
clear()
});
})
</script>
</body>
</html>
And this is some of the testing-code results:

Here, the name is obtained from split first part of filename
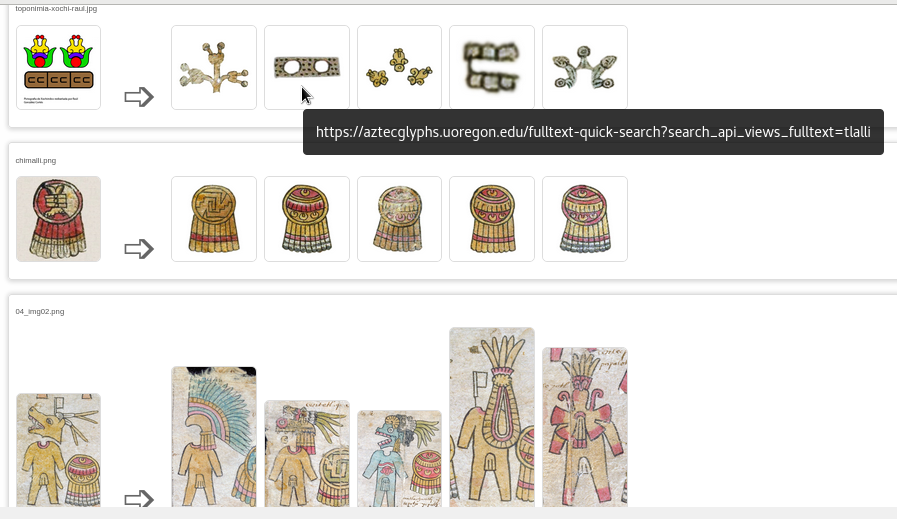
This is the built URL with splitted filename

In this example we can observe how “tonatiuh” (Sun) glyph matches with itself, but also with “chalchihuitl”, “xihuitl” and “ihuitl”, shinning elements in a circular form surrounded by 4 small balls in corners. In this case, “ihuitl” has a 75% o similarity with the comparison image
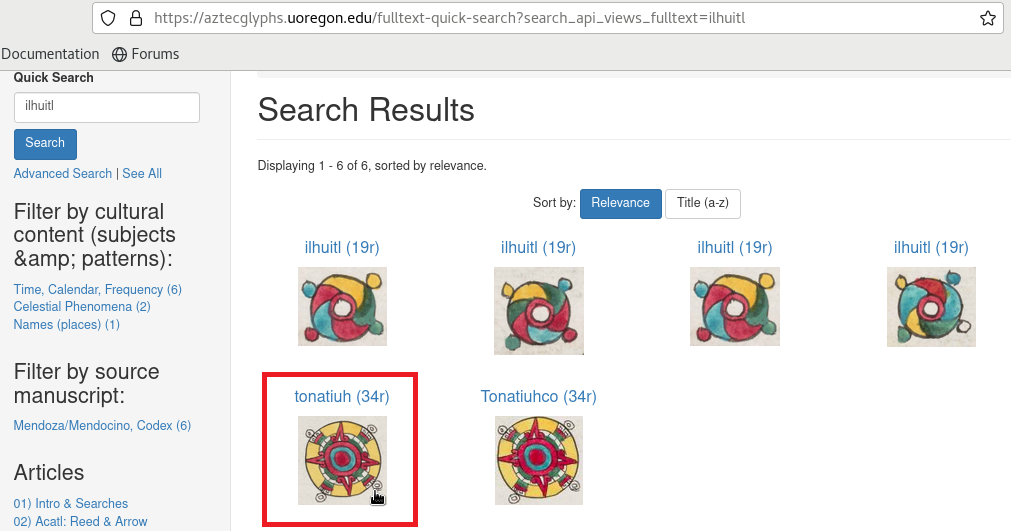
On image click, a new tab opens with the term-search in Visual Lexicon website. When click on “ihuitl” we can observe “ihuitl” entries but also “tonatiuh” ones
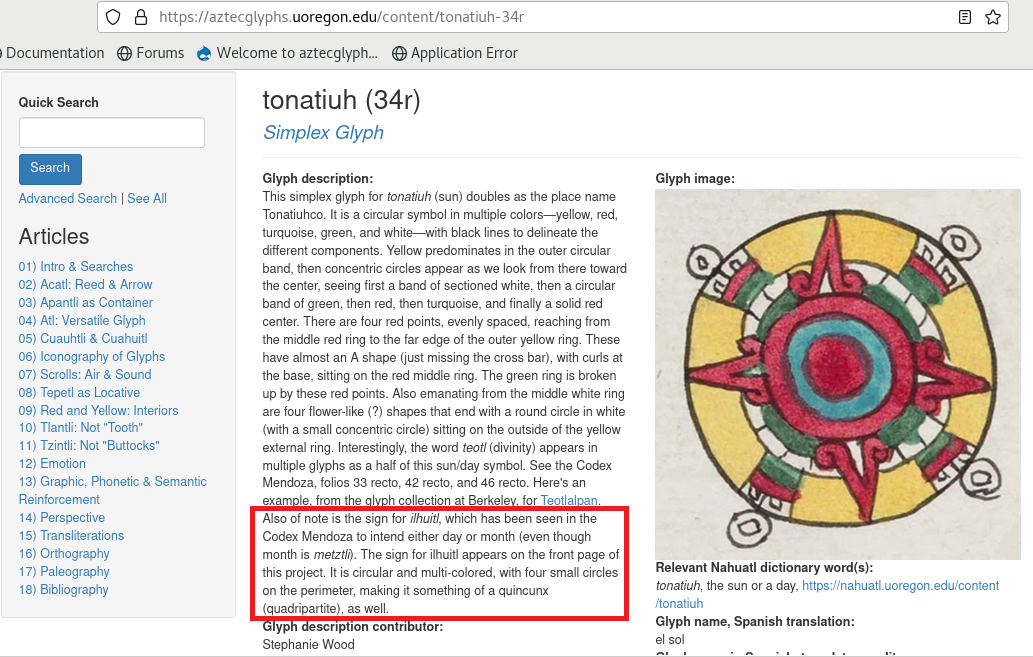
Curiously, “ihuitl” is related with “tonatiuh” glyph at some point, as we can read in the description. So, not bad for the algorithm this time! :-)
Final Changelog:
As a continuity of previous GSoC2021 project, there is a list of new implementations and changes:
-
Default upload folder changed from app local ‘static/uploads/’ to ‘/tmp/aztecglyphrecongitiontempuploads/’ (script creates this tmp subfolder if not exists)
-
The app shows now the first 6 closed images related with user’s uploaded image instead of just 5
-
Results are printed in screen under 100 px instead 120 for fit with phone devices and some browsers
-
Fixed: first most closed result is now readed from array(0) position, instead 1.
-
Glyph info is obtained from first part of the filename split
-
Each closed image is now also linked on-click to Visual Recognition of Aztec Hieroglyphs site’s results
-
Cosine distance is converted in percentil amount of similarity between user’s image and closed image
-
A proper match is >85% of similarity (very few times in lower ranks 80-75%)
-
Glyph name and percentage are shown at image mouse-over
-
Cropping glyphs with surrounded color material can give abnomal results due to full-color image comparison
WEEK 10
15 - 21 AGO
This week, I am going to get some results with a set of glyph names of Aztec rulers (Acamapichtli, Itzcoatl and Moctezuma Xocoyotzin). I am going to store them in “static/samples/” folder but not Medoza Codex examples. Mendoza Codex will be our “comparison tester”, so that’s why they are not included in test-dataset as the first results will be itself with a 100% of similarity. This will help us to find next “related” codex if we want to add more glyphs in future.

This is the set of glyph names in diferent codex for Acamapichtli ruler (47 in total, but first and second are from Mendoza Codex, so 45 will be use as test-dataset). And these are the results:
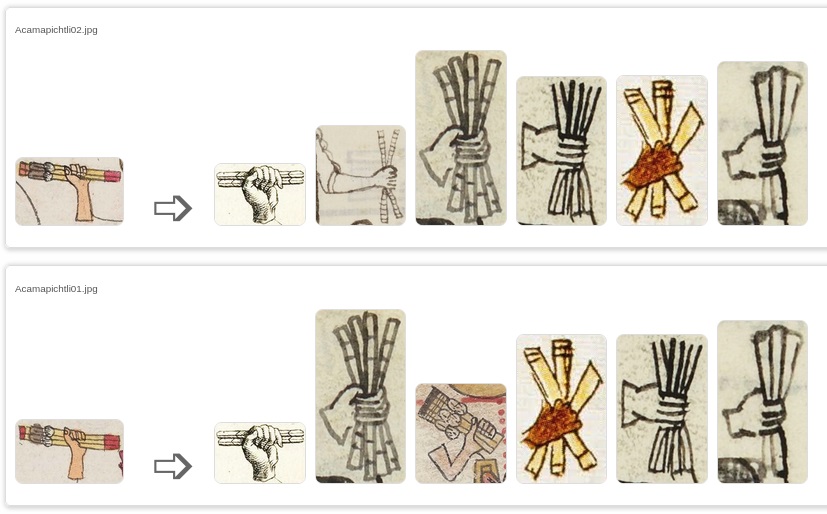
Acamapichtli02.jpg: 1. Clavijero (75%), 2. Codex Mexicain Depuis 1221 (71%), 3. Matrícula de Huexotzinco (71%), 4. Matrícula de Huexotzinco (70%), 5. Codex Vaticanus A (68%), 6. Matrícula de Huexotzinco (68%).
Acamapichtli01.jpg: 1. Clavijero (78%), 2. Matrícula de Huexotzinco (72%), 3. Tira de Tepechpan (70%), 4. Codex Vaticanus A (68%), 5. Matrícula de Huexotzinco (68%), 6. Matrícula de Huexotzinco (66%).

This is the set of glyph names in diferent codex for Itzcoatl ruler (48 in total, but 2nd and 3th are from Mendoza Codex, so 46 will be use as test-dataset). And these are the results:

Itzcoatl CM 03.jpg: 1. Primeros Memoriales (79%), 2. Durán Codex (70%), 3. Ramírez Codex (70%), 4. Matrícula de Tributos “related codex” (69%), 5. Codex Mexicain Depuis 1221 (68%), 6. Durán Codex (68%).
Itzcoatl CM 02.jpg: 1. Primeros Memoriales (79%), 2. Durán Codex (73%), 3. Cozcatzin Codex (70%), 4. Durán Codex (69%), 5. Ramírez Codex (69%), Codex Vaticanus A (68%).

This is the set of glyph names in diferent codex for Moctezuma Xocoyotzin ruler (48 in total, but 9th is from Mendoza Codex, so 47 will be use as test-dataset). And these are the results:

Motecuhzoma CM 09.jpg: 1. Codex Vaticanus A (66%), 2. Clavijero (65%), 3. Primeros Memoriales (63%), 4. Florentino Codex (62%), 5. Tlaloc Stone (62%), 6. Cozcatzin Codex (61%).
We can observe how these Medoza Codex’s glyphs are related with “Primeros Memoriales”, “Clavijero - Storia Antica…”, “Matrícula de Huexotzinco”, “Durán Codex”, “Codex Vaticanus A”, “Florentino Codex”, and even with “Matrícula de Tributos”, a related codex we were working with in the first part of the project. Curiously, Storia Antica from Xavier Clavijero (a book from late-18th century and a fully european production) can easily be linked with Mendoza Codex, as many of its glyph-images matched at some point (and probably were inspired by Mendoza Codex).
Now, we are going to test all glyphs from Moctezuma Xocoyotzin (48) with full dataset (2725: Mendoza Codex and Matrícula de Tributos). But we are going to show here only those who matched with some visual attribute (in red) of his glyph name (diadem with/without noseplug/earplug, and long hair) that also is the regular glyph for “tecuhtli” (lord). As we know, Moctezuma is a spanish corruption for Mo-tecuh-zoma (original Aztec name) meaning “Our Angry Lord”.
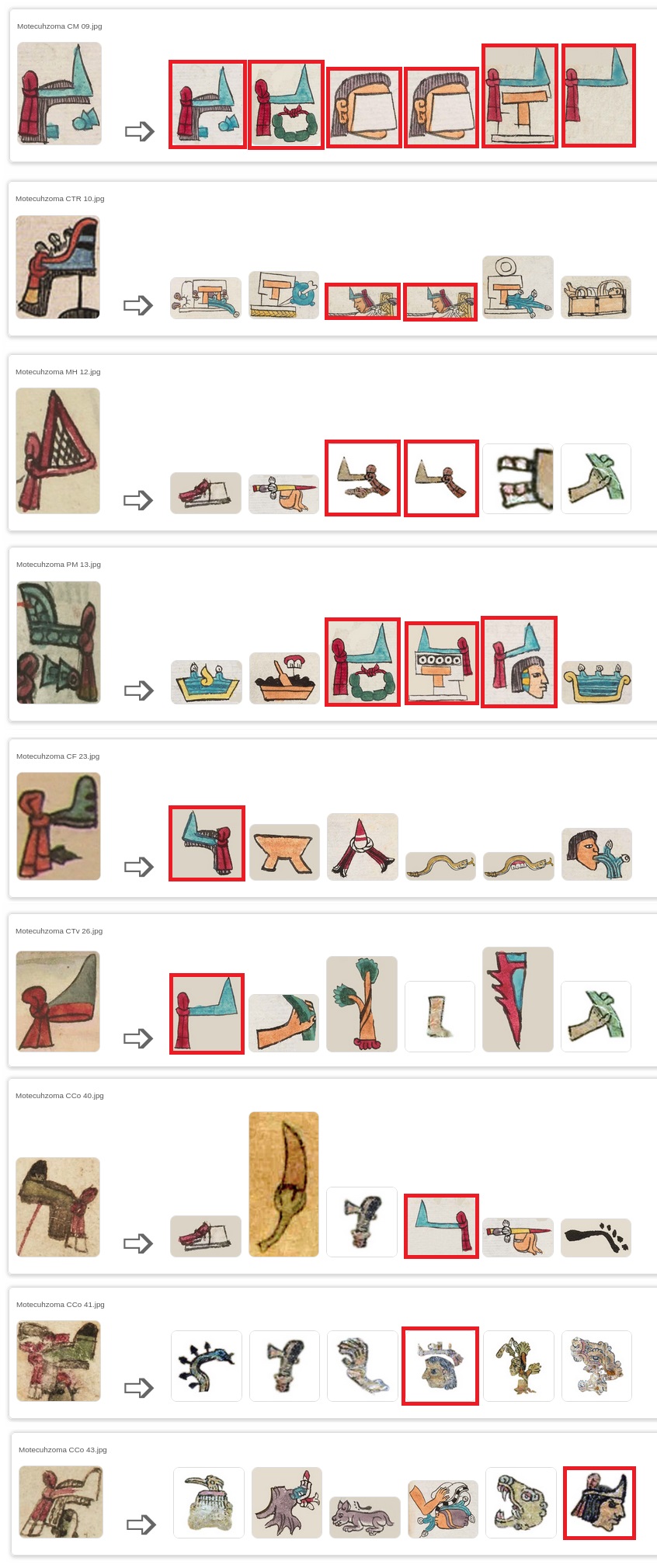
As we can observe only 9 of 48 (18.75%) show some visual attribute in its first six most closed results:
- Motecuhzoma CM 09.jpg (Mendoza Codex): 1. Motecuhzoma (itself, 100%), 2. Cozcatecuhtlan (79%), 3. Izquemecan (due to “long hair”, 77%), 4. ixtli (also due to “long hair”, 77%), 5. Tecalco (76%), 6. tecuhtli (74%).
- Motecuhzoma CTR 10.jpg (Telleriano-Remensis Codex): 3. mecania (due to “diadem”, 69%), 4. mecatl (also due to “diadem”, 69%).
- Motecuhzoma MH 12.jpg (Matrícula de Huexotzinco): 3. Cozcatecuhtlan (from Matrícula de Tributos, 66%), 4. tecuhtli (from Matrícula de Tributos, 65%).
- Motecuhzoma PM 13.jpg (Primeros Memoriales): 3. Cozcatecuhtlan (64%), 4. Tecpan (645), 5. Tlacatecuhtli (64%).
- Motecuhzoma CF 23.jpg (Florentino Codex): 1. tecuhtli (57%).
- Motecuhzoma CTv 26.jpg (Tovar Codex): 1. tecuhtli (63%).
- Motecuhzoma CCo 40.jpg (Cozcatzin Codex): 4. tecuhtli (59%).
- Motecuhzoma CCo 41.jpg (Cozcatzin Codex): 4. tlacochtecuhtli (from Matrícula de Tributos, 69%).
- Motecuhzmoa CCo 43.jpg (Cozcatzin Codex): 6. tecuhtli (from Matrícula de Tributos, 70%).
As expected Telleriano-Remensis, Matrícula de Huexotzinco, Primeros Memoriales, Florentino, Tovar and (in 3 cases of) Cozcatzin codex, show some visual attribute in the 6 most related glyphs.
WEEK 11
22 - 28 AGO
Provided (updated) a functional URL with new code and new dataset of images:
Aztec Glyph Recognition App (v.2)
WEEK 12
29 AGO - 4 SEP
- Report week
SEP 5 ~ END;
5 SEP - 12 SEP
Contributor’s final report:
Finally, the code was deployed also in UOregon’s server, as AztecGlyphRecognition URL